How to process a Amazon Kinesis stream using AWS Lambda and store them in DynamoDB



How to create a Kinesis Stream and process it in a serverless fashion using AWS Lambda
Kinesis Stream
Amazon Kinesis Data Streams is a serverless streaming data service that makes it easy to capture, process, and store data streams at any scale.
Creation of a Kinesis Stream using CloudFormation
Let's create a Kinesis Stream:
MyStream:
Type: AWS::Kinesis::Stream
Properties:
Name: "my-stream"
RetentionPeriodHours: 168
ShardCount: 1
StreamEncryption:
EncryptionType: KMS
KeyId: alias/aws/kinesis
We can put records to the stream using the AWS CLI.
aws kinesis put-record --stream-name my-stream --partition-key 123 --data testdata
Trigger a lambda function every time a new record arrives the stream
LambdaTriggerKinesisStream:
Type: AWS::Lambda::EventSourceMapping
Properties:
BatchSize: 1
Enabled: truer
EventSourceArn: !GetAtt MyStream.Arn
FunctionName: !GetAtt MyLambda.Arn
MaximumBatchingWindowInSeconds: 0
StartingPosition: LATEST
As you can see we are using the !GetAtt function to get the ARN from two resources, the first one is the Stream which was already created, the second one is the Lambda function that we are going to create.
So in the title says we are going to be saving the records to a DynamoDB table, lets create that one first.
DynamoDB
We are going to define the partition key as an ID, and the sort key as the time of the event. Lets assume that our access pattern would always be by ID.
DynamoDBTable:
Type: AWS::DynamoDB::Table
DeletionPolicy: Retain
UpdateReplacePolicy: Retain
Properties:
TableName: "my-dynamodb"
AttributeDefinitions:
# Partition Key
- AttributeName: "id"
AttributeType: "S"
- AttributeName: "timestamp"
AttributeType: "S"
KeySchema:
- AttributeName: "id"
KeyType: "HASH"
- AttributeName: "timestamp"
KeyType: RANGE
SSESpecification:
SSEEnabled: true
BillingMode: PAY_PER_REQUEST
IAM Role
This role will allow our function to only write records to only this DynamoDB table.
MyLambdaRole:
Type: AWS::IAM::Role
Properties:
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaKinesisExecutionRole
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- sts:AssumeRole
Path: "/"
Policies:
- PolicyName: ReadWriteDynamoPolicy
PolicyDocument:
Version: "2012-10-17"
Statement:
- Action:
- "dynamodb:List*"
- "dynamodb:DescribeReservedCapacity*"
- "dynamodb:DescribeLimits"
- "dynamodb:DescribeTimeToLive"
Resource: "*"
Effect: "Allow"
- Action:
- "dynamodb:BatchGet*"
- "dynamodb:DescribeStream"
- "dynamodb:DescribeTable"
- "dynamodb:Get*"
- "dynamodb:Query"
- "dynamodb:Scan"
- "dynamodb:BatchWrite*"
- "dynamodb:Update*"
- "dynamodb:PutItem"
Resource:
- "arn:aws:dynamodb:*:*:table/my-dynamodb"
Effect: "Allow"
Lambda function
Now that we have the stream, the DynamoDB table and the role we can focus on the Lambda function.
MyLambda:
Type: AWS::Lambda::Function
Properties:
FunctionName: "my-lambda"
Code:
ZipFile: >
const AWS = require('aws-sdk');
const docClient = new AWS.DynamoDB.DocumentClient({apiVersion: '2012-08-10'});
exports.handler = async function(event, context) {
// We only process one event at the time
const r = event.Records[0];
const { data, approximateArrivalTimestamp } = r.kinesis;
const dynamoDbTable = process.env["TABLE"];
if(dynamoDbTable === undefined){
console.error(`Can't log the event ${event}. Need to configure the dynamodb table.`);
return;
}
const decodedRecordData = Buffer.from(data, 'base64');
const jsonData = JSON.parse(decodedRecordData.toString());
const item = {
timestamp: new Date(parseInt(`${approximateArrivalTimestamp}`.replace('.', ''))).toISOString(),
...jsonData,
};
const params = {
TableName: dynamoDbTable,
Item: item
};
console.log(`Adding a new item: ${JSON.stringify(params, null, 2)}`);
const response = await docClient.put(params).promise();
console.log(`Response: ${JSON.stringify(response, null, 2)}`);
}
Handler: index.handler
Role: !GetAtt MyLambdaRole.Arn
Runtime: nodejs12.x
MemorySize: 256
Timeout: 30
Environment:
Variables:
TABLE: !Ref DynamoDBTable
Diagram
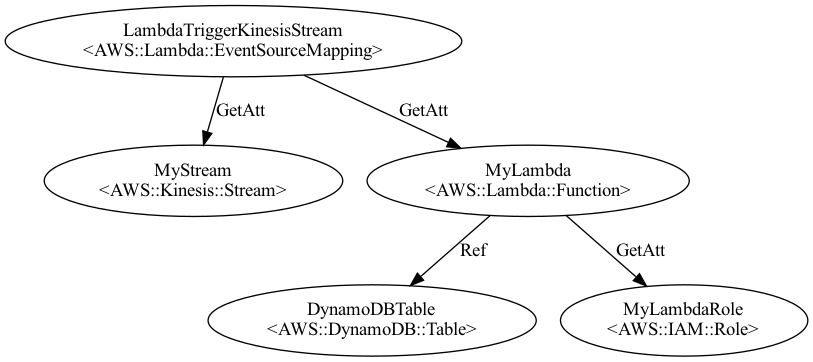
Conclusion
We just created all the resources to be able to put and consumer records from a Kinesis Stream. We saw how you can attach a Lambda function to a Kinesis stream to process data. Multiple Lambda functions can consume from a single Kinesis stream for different kinds of processing independently. We also created a simple Lambda function which will store every record into DynamoDB.
Source code
Find the source code of this post.